
You are here
Visualizing Token Limits in Large Language Models
Posted by Jim Craner on October 28, 2023
1. "Context Window"
Attendees of our AI workshops will remember that modern AI language tools, known as Large Language Models ("LLM"), can only read and generate a certain amount of text at a time. The text that you submit into an LLM, and the text that the LLM generates in response, are limited. This limit of the input and the output is called the "context window."
The input and output are considered together. So,
- really long input = less "space" left for the AI to output text
- really short input = lots of "space" for the AI response
For simple AI chat applications, this doesn't really matter: tools like ChatGPT can remember quite a bit of your previous conversation. But if you're feeding data into an AI tool or application -- such as book text, catalog data, spreadsheets, etc. -- you need to carefully consider your input and output constraints.
2. "Tokens"
"Tokens" are the "chunks" of text that AI reads and/or writes. When you type a sentence, in English, into ChatGPT, your sentence is broken up into these "tokens." Your "tokens" are fed into the AI model and it generates new "tokens" which are then converted back into English (or whatever human language you requested).
- a "token" is just a chunk of text
- a token can be a single character like "a" or "P" or "?"
- a token can be an entire word like "pickle"
- the length of a token is determined by a complex algorithm
- OpenAI's guidelines:
- on average, a token is about 4 characters
- on average, 100 tokens is about 75 words
These are just guidelines. Different types of language and different languages are tokenized in different ways. OpenAI provides a tool to calculate the length of tokens. Here's an example showing a sentence "I need to stop at the supermarket." and the resulting tokens, each color-coded.
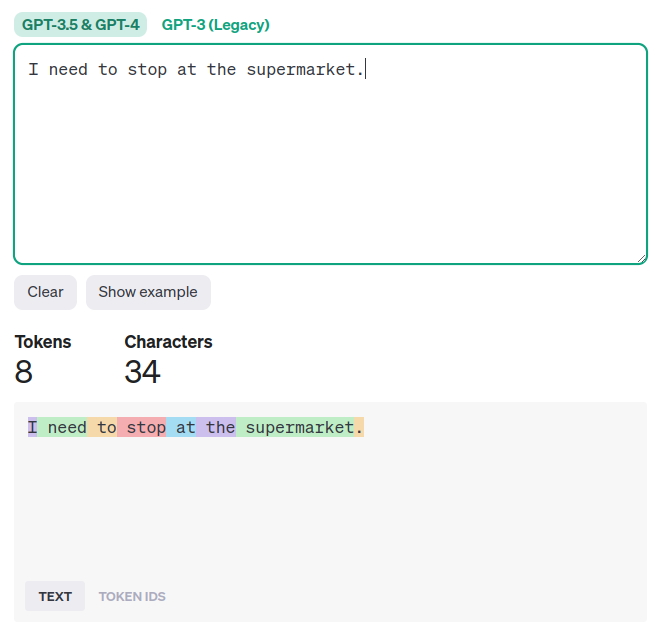
Here are some more examples of text and the corresponding token lengths!
| Text | Tokens | Characters | Image |
|---|---|---|---|
| "This sentence contains six tokens." | 6 | 36 |  |
| Gettysburg Address | 310 | 1,453 |  |
| US Declaration of Independence (no signatures) | 1,638 | 8,147 |  |
| Anne of Green Gables, chapter 1 | 3,549 | 15,585 |  |
3. Context Window Token Limits
So, tokens are how AI converts human text into an "AI-ready format" and then back to human language. The "context window" of an AI specifies how large the input to, and output from, an AI can be. The context window is measured in tokens!
Note: OpenAI released GPT-4-Turbo in November 2023, with a new 128,000 token limit! That's enough for a novel.
- GPT-3.5, an older AI released in 2022, initially had a context window of approximately 4,000 tokens, or approximately 3,000 words.
- Input a passage of text that is 2,500 words; that leaves approximately 500 words for the response.
- Input a short prompt, just 50 words. That leaves approximately 2,950 words for a very long response.
- GPT-3.5 is now available in a large version with a 16,000 token context limit (approximately 12,000 words)
- GPT-4, released in 2023, has a context window of approximately 8,000 tokens, or approximately 6,000 words.
- You could input a short story of 5,000 words into GPT-4, leaving approximately 1,000 words remaining for the response.
- You could input a simple 10-word prompt into GPT-4, leaving almost the entire 6,000 word context window available for a very lengthy response.
- GPT-4 is now available, on a limited basis, in a 32,000 token context limit version.
4. Token Costs
As mentioned, tokens are how AI reads and writes language. The use of tokens is also how AI companies charge other companies for using their AI services. Again, this is not relevant if you're just using ChatGPT. It's only relevant if you're building an AI application to process large amounts of text using an AI company's service. This table is based on OpenAI pricing data current as of 18 Oct 2023.
| MODEL | LIMIT | INPUT ($/token) | OUTPUT ($/token) | 500in/500out | 1000in/1000out | MillionIn/MillionOut | AllInCostMax | AllOutCostMax |
|---|---|---|---|---|---|---|---|---|
| gpt-3.5-turbo | 4000 | 0.0000015 | 0.000002 | $0.00 | $0.00 | $3.50 | $0.01 | $0.01 |
| gpt-3.5-turbo-16k | 16000 | 0.000003 | 0.000004 | $0.00 | $0.01 | $7.00 | $0.05 | $0.06 |
| gpt-3.5-turbo-instruct | 4000 | |||||||
| gpt-3.5-finetuned | 0.000012 | 0.000016 | $0.01 | $0.03 | $28.00 | |||
| gpt-4 | 8000 | 0.00003 | 0.00006 | $0.05 | $0.09 | $90.00 | $0.24 | $0.48 |
| gpt-4-32k | 32000 | 0.00006 | 0.00012 | $0.09 | $0.18 | $180.00 | $1.92 | $3.84 |